Understanding LLM Memory Requirements: From Parameters to VRAM
The first article in our GPU Capacity Planning for LLM Models series

When deploying Large Language Models (LLMs) in production, one of the most critical—and often misunderstood—aspects of infrastructure planning is accurately estimating GPU memory requirements. The gap between a model's parameter count and its actual VRAM footprint can be substantial, leading to costly over-provisioning or frustrating out-of-memory errors that derail deployments.
This article provides a comprehensive framework for understanding and calculating LLM memory requirements, moving beyond simple parameter counts to account for the full spectrum of memory overhead that occurs in real-world deployments.
The Parameter Count Illusion
Most discussions around LLM hardware requirements start and end with parameter counts: "Llama 2 70B has 70 billion parameters, so it needs X amount of memory." This oversimplification has led many teams astray. Parameter count is just the starting point—the actual memory footprint depends on precision format, inference patterns, batch sizes, and numerous overhead factors.
Consider this fundamental calculation: A quick rule of thumb for LLM serving for models loaded in "half precision" - i.e. 16 bits, is approximately 2GB of GPU memory per 1B parameters in the model. For a 70B parameter model like Llama 3, this translates to roughly 140GB just for the model weights in FP16 precision. But this is only the beginning of our memory story.
Breaking Down Memory Components
1. Model Weights: The Foundation
The model weights represent the core parameters that define the LLM. The memory requirement scales directly with parameter count and precision:
Memory Formula for Model Weights:
Memory (GB) = Parameters × Precision (bytes) ÷ 1,073,741,824
Common Precision Formats:
FP32 (32-bit): 4 bytes per parameter
FP16 (16-bit): 2 bytes per parameter
INT8 (8-bit): 1 byte per parameter
INT4 (4-bit): 0.5 bytes per parameter
1 Parameters (Weights) = 4 Bytes (FP32) To calculate the memory required for 1 billion parameters we will multiply 4 bytes with a billion which would give us around 4 GB.
Example: Llama 2 70B Memory Requirements by Precision
FP32: 70B × 4 bytes = 280GB
FP16: 70B × 2 bytes = 140GB
INT8: 70B × 1 byte = 70GB
INT4: 70B × 0.5 bytes = 35GB
2. KV Cache: The Hidden Memory Consumer
The Key-Value (KV) cache is where many memory estimates go wrong. During inference, transformers cache the key and value matrices from previous tokens to avoid redundant computations. This cache grows linearly with sequence length and batch size.
KV Cache Memory Formula:
KV_Cache (GB) = 2 × Batch_Size × Sequence_Length × Hidden_Dim × Num_Layers × Precision ÷ 1,073,741,824
For a model like Llama 2 70B with typical parameters:
Hidden dimension: 8,192
Number of layers: 80
Sequence length: 4,096 tokens
Batch size: 8
Precision: FP16 (2 bytes)
KV Cache = 2 × 8 × 4,096 × 8,192 × 80 × 2 ÷ 1,073,741,824 ≈ 32GB
This represents nearly 25% additional memory overhead just for the KV cache with modest batch sizes.
3. Activation Memory: Temporary but Significant
During forward passes, models store intermediate activations that can consume substantial memory, especially with larger batch sizes. Unlike KV cache, activation memory is temporary but peaks during computation.
Activation Memory Estimation:
Activations ≈ Batch_Size × Sequence_Length × Hidden_Dim × 12 × Precision
The factor of 12 is an approximation covering attention scores, intermediate MLPs, and other temporary computations in transformer architectures.
4. Framework and System Overhead
PyTorch, CUDA kernels, and other system components add their own overhead:
PyTorch overhead: 2-4GB base memory
CUDA context: 1-2GB per GPU
Framework buffers: 5-10% of total model memory
Comprehensive Memory Calculation Framework
Bringing all components together, here's the complete memory estimation formula:
Total_Memory = Model_Weights + KV_Cache + Activations + System_Overhead + Safety_Buffer
Safety Buffer: Always add 10-20% buffer for memory fragmentation and unexpected spikes.
Real-World Example: Llama 2 70B Deployment
Let's calculate memory requirements for serving Llama 2 70B with realistic production parameters:
Configuration:
Model precision: FP16
Batch size: 16
Max sequence length: 4,096
Context window: 4,096
Memory Breakdown:
Model weights: 140GB (70B × 2 bytes)
KV cache: 64GB (scaling with batch size 16)
Activations: ~24GB (peak during inference)
System overhead: ~8GB (PyTorch + CUDA)
Safety buffer: ~24GB (10% buffer)
Total estimated memory: ~260GB
A single A100 80GB wouldn't be enough, but 2x A100 80GB should handle this workload, though you'd want at least 4x A100 80GB for production reliability and headroom.
Popular Model Memory Requirements
Here's a practical reference table for common LLM models in production:
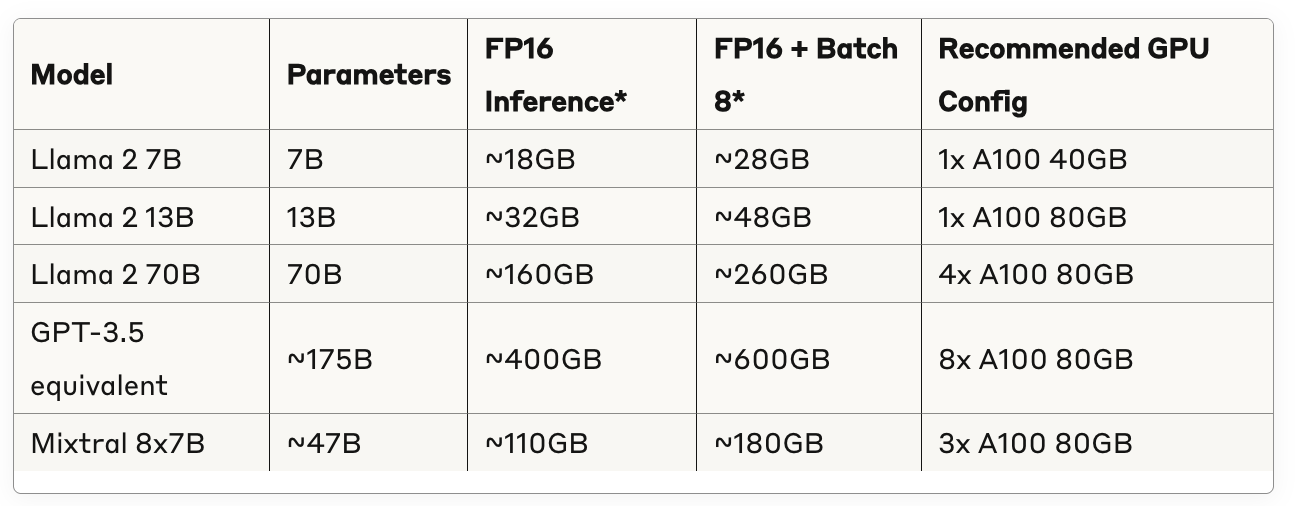
*Includes model weights, KV cache, system overhead, and 10% safety buffer
Optimization Strategies for Memory Efficiency
1. Precision Optimization
Start with FP16: Maintains quality while halving memory requirements
Consider INT8: This is significantly higher than the 2GB per 1B parameters needed for inference, due to the additional memory required for optimizer states during training, but inference can benefit from quantization
Explore INT4: Experimental but promising for resource-constrained deployments
2. Dynamic Batching
Instead of fixed batch sizes, implement dynamic batching that adjusts based on sequence lengths and available memory. This maximizes throughput while preventing OOM errors.
3. KV Cache Management
Sliding window attention: Limit cache to recent tokens
Cache compression: Techniques like sparse attention patterns
Multi-stage caching: Keep frequently accessed keys/values in fast memory
4. Memory-Mapped Models
For models too large for single GPU memory, memory-mapped loading can stream weights from system RAM or NVMe storage, though with latency trade-offs.
Monitoring and Validation
Key Metrics to Track
Peak memory usage: Monitor during different batch sizes and sequence lengths
Memory fragmentation: Track available vs. allocated memory over time
OOM frequency: Count and categorize out-of-memory errors
Memory efficiency: Actual utilization vs. theoretical calculations
Validation Checklist
[ ] Test memory usage across different batch sizes (1, 4, 8, 16, 32)
[ ] Validate with maximum expected sequence lengths
[ ] Measure peak memory during concurrent requests
[ ] Account for model loading/unloading overhead
[ ] Test memory behavior during scaling events
Looking Ahead
Understanding LLM memory requirements is the foundation for effective GPU capacity planning. In our next article, we'll dive deep into GPU architectures and how different hardware choices impact not just memory capacity, but memory bandwidth, compute efficiency, and total cost of ownership.
The key takeaway: parameter count is just the starting point. Successful LLM deployments require comprehensive memory modeling that accounts for inference patterns, batch sizes, and real-world overhead. By building this foundation, you'll avoid the costly surprises that plague many production LLM deployments.
Next in series: "GPU Architecture Deep Dive: Choosing the Right Hardware for LLM Workloads"
About this series: This is the first article in our comprehensive guide to GPU capacity planning for Large Language Models. Each article builds practical knowledge for ML engineers and infrastructure architects deploying LLMs at scale.